
O Open-AudIT é um Sistema Open Source de Gerenciamento de Rede, Auditoria
e Inventário. Com essa ferramenta é possível verificar quais
equipamentos e softwares estão presentes em uma determinada rede.
Abaixo demonstrarei uma instalação do serviço WEB (servidor web) em diferentes modos, para que os que usam distribuições distintas de Linux possam aproveitar o software open-source open-audit.
Por via das dúvidas, vamos solicitar uma breve atualização dos repositórios do seu gerenciador de pacotes e do sistema operacional em si.
Acesse o terminal de sua preferência e digite os comandos:
$ sudo apt-get update (atualiza sua lista de repositórios)
$ sudo apt-get upgrade (atualiza os pacotes que achar necessário)
Servidor web:
$ sudo apt-get install apache2 python openssl phpmyadmin php5
$ sudo apt-get install php5-gd
$ sudo apt-get install php-pear php5-gd php5-xsl curl libcurl3 libcurl3-dev php5-curl
Dica: Faça uma instalação full do sistema operacional, todos os componentes. Friso isso pois é muito chato você desejar instalar um novo servidor e ter problemas com bibliotecas C#, C++, make, mod_php5, entre outros. Instale tudo!
RPMs necessários:
Todos os pacotes RPM encontram-se nos CDs de instalação, mas caso precise achar na internet eu recomendo o site: http://rpm.pbone.net/
Mas se mesmo assim encontre dúvidas, explicarei o processo de instalação.
Desinstale caso exista uma versão do Apache e MySQL:
# rpm -e httpd mysql
Faça o download e instale os pacotes RPM do MySQL do servidor, não optar por mudar a senha no banco de dados MySQL:
# rpm -ivh MySQL-client-5.0.20-0.glibc23.i386.rpm MySQL-server-5.0.20-0.glibc23.i386.rpm MySQL-shared-5.0.20-0.glibc23.i386.rpm
# mysql_install_db
# /sbin/ldconfig
Faça o download, descompacte e instale o Apache2 do source da apache.org:
# mv httpd-2.0.55.tar.gz /usr/local/; cd /usr/local/
# tar -xzvf httpd-2.0.55.tar.gz
# cd httpd-2.0.55
# ./configure --enable-so
# make
# make install
Inicie o Apache:
# /usr/local/apache2/bin/apachectl start
Teste para verificar se está funcionando. Pelo seu browser preferido acesse:
http://ip_do_servidor/
Pare o Apache:
# /usr/local/apache2/bin/apachectl stop
Baixe, descompacte e instale o php do sourcephp.net:
# mv php-4.4.1.tar.gz /usr/local/; cd /usr/local/
# tar -xzvf php-4.4.1.tar.gz; cd php-4.4.1/
# ./configure --with-apxs2=/usr/local/apache2/bin/apxs --with-mysql
# make
# make install
Adicione em seu httpd.conf:
Reinicie seu Apache:
# /usr/local/apache2/bin/apachectl restart
Primeiramente faça o download do pacote no SourceForge.net.
Caso o link apresente erros, acesse a página do software em:
Agora, descompacte o pacote ".zip" em seu diretório onde ficam os documentos, sites e tudo mais que você publica em seu web-server.
Abra seu terminal e digite:
# gunzip nomedoarquivo
Aos que tiverem dúvidas sobre o diretório de onde ficam os documentos do Apache, favor consultar seu arquivo de configuração.
Procure pelo parâmetro:
Em muitas distribuições, pode ficar como:
Por isto verifique onde ficam localizadas seus sites e publicações.
Após isto, dê permissão a pasta e todas suas sub-pastas usando o comando:
# chmod 777 /var/www/html/open-audit/ -Rf
Apenas para instalar vamos dar permissão total, após isto você deve alterar as permissões que melhor administre.
Vamos para o último passo da instalação.
Acesse pelo seu browser favorito o openaudit:
http://ip_do_servidor/open-audit
Conforme a tela abaixo:
 Escolha o idioma "pt_br", prossiga com a instalação e aparecerá a tela conforme a imagem abaixo:
Escolha o idioma "pt_br", prossiga com a instalação e aparecerá a tela conforme a imagem abaixo:
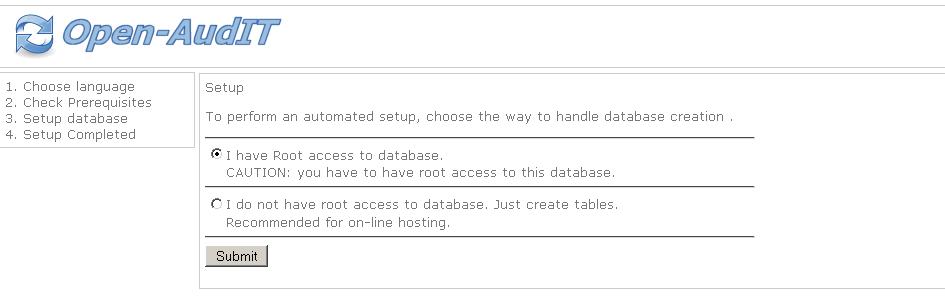
 Agora escolha a 1a. opção, que é a que informa que você possui acesso
completo ao banco de dados, para criar o banco e as tabelas, conforme a
imagem abaixo:
Agora escolha a 1a. opção, que é a que informa que você possui acesso
completo ao banco de dados, para criar o banco e as tabelas, conforme a
imagem abaixo:
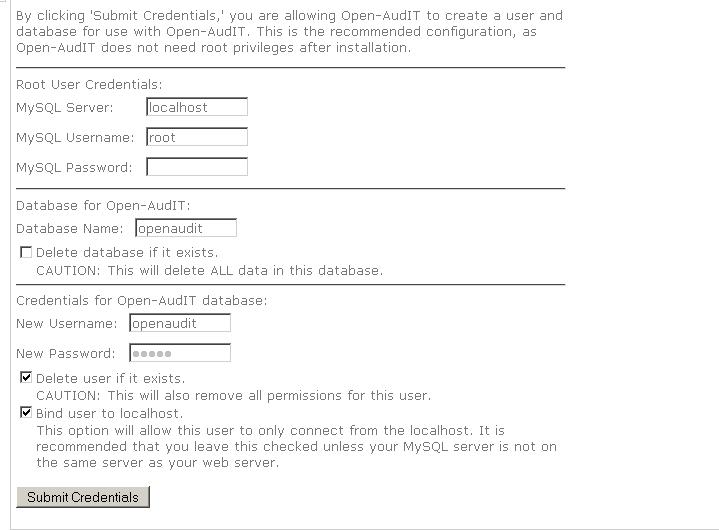
 Agora informe os parâmetros de seu banco de dados MySQL, conforme a imagem abaixo:
Agora informe os parâmetros de seu banco de dados MySQL, conforme a imagem abaixo:
 PARABÉNS!
PARABÉNS!
 Você conseguiu instalar com sucesso o software! Agora vamos para as configurações e extras.
Você conseguiu instalar com sucesso o software! Agora vamos para as configurações e extras.
Acesse o arquivo do open-audit na pasta scripts, localizado em /var/www/html/open-audit/scripts/audit.config.
Você pode configurar da maneira que desejar, existem muitos detalhes interessantes, mas abaixo vão os parâmetros essenciais:
Tudo foi instalado, e agora? Como vou alimentá-lo? Como vou auditar e criar o inventário dos computadores?
http://ip_do_servidor/open-audit
Acesse o menu a sua esquerda e clique em ADMINISTRAÇÃO -> AUDITE ESTA MÁQUINA, conforme a imagem abaixo:
 Você será redirecionado para efetuar um download de um script em .vbs.
Você será redirecionado para efetuar um download de um script em .vbs.
Execute este script e tenha paciência, pois em algumas máquinas pode demorar.
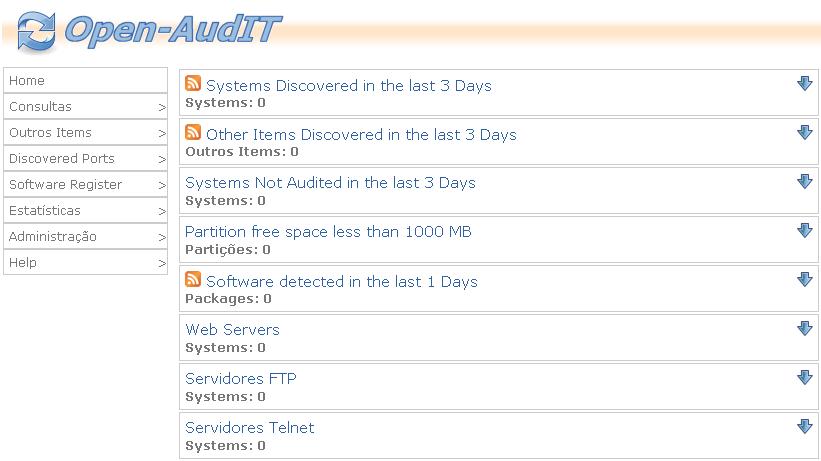
Quando o script acabar, acesse novamente o open-audit e verifique se a máquina já foi auditada, conforme a imagem abaixo:
 Ele informa quase tudo da estação, desde monitor, placa de rede,
processador, HD, basta navegar pelos seus menus do sistema open-audit.
Ele informa quase tudo da estação, desde monitor, placa de rede,
processador, HD, basta navegar pelos seus menus do sistema open-audit.
Mas como auditar um Linux?
Bom, também existe esta opção, porém ela não é a das mais simples, pelo simples motivo que cada distribuição possui sua gama de pacotes, gerenciadores de pacotes e tudo mais.
Mas para auditar, faça o seguinte procedimento:
Edite o arquivo /var/www/openaudit/scripts/audit-linux.sh.
Altera a linha:
OA_SUBMIT_URL=http://salma/openaudit/admin_pc_add_2.php
para o endereço correto do servidor, como por exemplo:
Salve o arquivo e dê permissão de execução através do comando:
# chmod a+x /var/www/openaudit/scripts/audit-linux.sh
Execute este script.
Podem retornar diversos erros e avisos, cada um deve ser analisado, pois no script testa se tal pacote é usado e tudo mais, vale a pena investigar cada aviso.
Primeiro, pegue aquele script .vbs que você usou para auditar aquela máquina com sistema operacional Windows e salve na rede do seu domínio com as devidas permissões. Pode salvar no SAMBA também, eu por exemplo o uso.
Nos scripts de logon dos usuários do Windows, edite a .bat que você usa ou a crie, caso não use, com o seguintes comandos:
Reparem que alterei aquele nome gigante do script em .vbs para somente auditar.vbs, pois fica mais fácil administrar.
Quando o usuário se logar no domínio, ele vai executar o script e enviar para o servidor.
Atenção, o script devido a sua carga de requisições e dados a capturar pode demorar de acordo com a estação de trabalho e a rede local.
Fontes: Latinoware, Viva o Linux
Requisitos necessários em diferentes distribuições Linux
Requisitos necessários são:- Sistema Operacional Linux (Kernel 2.4.x.x ou 2.6.x.x) ou Windows
- Serviço WEB (Apache, nginx, etc) com suporte a php 4 de preferência php 5.
- Open-Audit (uma cópia do desenvolvimento).
Abaixo demonstrarei uma instalação do serviço WEB (servidor web) em diferentes modos, para que os que usam distribuições distintas de Linux possam aproveitar o software open-source open-audit.
Instalação via apt-get (Debian´s like)
Primeiramente vamos partir do ponto que você já tem um sistema operacional Linux totalmente instalado e funcional, e que usa preferencialmente um gerenciador de pacotes do estilo "apt-get".Por via das dúvidas, vamos solicitar uma breve atualização dos repositórios do seu gerenciador de pacotes e do sistema operacional em si.
Acesse o terminal de sua preferência e digite os comandos:
$ sudo apt-get update (atualiza sua lista de repositórios)
$ sudo apt-get upgrade (atualiza os pacotes que achar necessário)
Servidor web:
$ sudo apt-get install apache2 python openssl phpmyadmin php5
$ sudo apt-get install php5-gd
$ sudo apt-get install php-pear php5-gd php5-xsl curl libcurl3 libcurl3-dev php5-curl
Instalação via Red Hat, Fedora, e RPMs like
Vamos partir do ponto que você já tem um sistema operacional Linux totalmente instalado e funcional, e que usa gerenciador de pacotes estilo RPM, geralmente presente em distribuições como Red Hat, Fedora, openSUSE, CentOS, entre outras.Dica: Faça uma instalação full do sistema operacional, todos os componentes. Friso isso pois é muito chato você desejar instalar um novo servidor e ter problemas com bibliotecas C#, C++, make, mod_php5, entre outros. Instale tudo!
RPMs necessários:
- APACHE2
- PHP5
- PHP5-GD
- MYSQL-SERVER
Todos os pacotes RPM encontram-se nos CDs de instalação, mas caso precise achar na internet eu recomendo o site: http://rpm.pbone.net/
Mas se mesmo assim encontre dúvidas, explicarei o processo de instalação.
Desinstale caso exista uma versão do Apache e MySQL:
# rpm -e httpd mysql
Faça o download e instale os pacotes RPM do MySQL do servidor, não optar por mudar a senha no banco de dados MySQL:
# rpm -ivh MySQL-client-5.0.20-0.glibc23.i386.rpm MySQL-server-5.0.20-0.glibc23.i386.rpm MySQL-shared-5.0.20-0.glibc23.i386.rpm
# mysql_install_db
# /sbin/ldconfig
Faça o download, descompacte e instale o Apache2 do source da apache.org:
# mv httpd-2.0.55.tar.gz /usr/local/; cd /usr/local/
# tar -xzvf httpd-2.0.55.tar.gz
# cd httpd-2.0.55
# ./configure --enable-so
# make
# make install
Inicie o Apache:
# /usr/local/apache2/bin/apachectl start
Teste para verificar se está funcionando. Pelo seu browser preferido acesse:
http://ip_do_servidor/
Pare o Apache:
# /usr/local/apache2/bin/apachectl stop
Baixe, descompacte e instale o php do sourcephp.net:
# mv php-4.4.1.tar.gz /usr/local/; cd /usr/local/
# tar -xzvf php-4.4.1.tar.gz; cd php-4.4.1/
# ./configure --with-apxs2=/usr/local/apache2/bin/apxs --with-mysql
# make
# make install
Adicione em seu httpd.conf:
LoadModule php4_module modules/libphp4.so
AddType application/x-httpd-php .php .phtml
AddType application/x-httpd-php-source .phps
DirectoryIndex index.html index.php
AddType application/x-httpd-php .php .phtml
AddType application/x-httpd-php-source .phps
DirectoryIndex index.html index.php
Reinicie seu Apache:
# /usr/local/apache2/bin/apachectl restart
Instalação do Open-Audit
Agora o mais importante, a instalação.Primeiramente faça o download do pacote no SourceForge.net.
Caso o link apresente erros, acesse a página do software em:
Agora, descompacte o pacote ".zip" em seu diretório onde ficam os documentos, sites e tudo mais que você publica em seu web-server.
Abra seu terminal e digite:
# gunzip nomedoarquivo
Aos que tiverem dúvidas sobre o diretório de onde ficam os documentos do Apache, favor consultar seu arquivo de configuração.
Procure pelo parâmetro:
DocumentRoot "/var/www/html"
Em muitas distribuições, pode ficar como:
DocumentRoot "/var/www"
Por isto verifique onde ficam localizadas seus sites e publicações.
Após isto, dê permissão a pasta e todas suas sub-pastas usando o comando:
# chmod 777 /var/www/html/open-audit/ -Rf
Apenas para instalar vamos dar permissão total, após isto você deve alterar as permissões que melhor administre.
Vamos para o último passo da instalação.
Acesse pelo seu browser favorito o openaudit:
http://ip_do_servidor/open-audit
Conforme a tela abaixo:


Extras e outras configurações
Agora vamos refinar a configuração do Open-Audit antes de alimentar com novas máquinas auditadas.Acesse o arquivo do open-audit na pasta scripts, localizado em /var/www/html/open-audit/scripts/audit.config.
Você pode configurar da maneira que desejar, existem muitos detalhes interessantes, mas abaixo vão os parâmetros essenciais:
'
' Standard audit section
'
audit_location = "r"
verbose = "n"
audit_host="http://192.168.50.60"
online = "yesxml"
strComputer = ""
ie_visible = "n"
ie_auto_submit = "y"
ie_submit_verbose = "n"
ie_form_page = audit_host + "http://192.168.50.60/openaudit/admin_pc_add_1.php"
non_ie_page = audit_host + "http://192.168.50.60/openaudit/admin_pc_add_2.php"
input_file = "pc_list_file.txt"
'
' Email authentication
'
'
email_to = "paulo@paulojr.info"
email_from = "paulo@paulojr.info"
'email_sender = "Open-AudIT"
email_server = 192.168.50.60 ' IP address or FQDN
email_port = "25" ' The SMTP port
email_auth = "1" ' 0 = Anonymous, 1 = Clear-text Authentication, 2 = NTLM
email_user_id = "paulo@teste.com" ' A valid Email account in user@domain format
email_user_pwd = "12345" ' The SMTP email password
email_use_ssl = "false" ' True/False
email_timeout = "90" ' In seconds
audit_local_domain = "y"
'
' Set domain_type = 'nt' for NT4 or SAMBA otherwise leave blank or set to ldap
'domain_type = "nt"
local_domain = "LDAP://example.local"
'
' Example Set Domain name for NT ONLY for LDAP use the above format
' NOTE This is Case Sensetive. See the example below.
'
'local_domain = "WinNT://IEXPLORE"
'local_domain = "WinNT://"
'
hfnet = "n"
Count = 0
number_of_audits = 10
script_name = "audit.vbs"
monitor_detect = "y"
printer_detect = "y"
software_audit = "y"
uuid_type = "uuid"
'
' Nmap section
'
nmap_tmp_cleanup = true ' Set this false if you want to leave the tmp files for analysis in your tmp folder
nmap_subnet = "192.168.50." ' The subnet you wish to scan
nmap_subnet_formatted = "192.168.050." ' The subnet padded with 0's
nmap_ie_form_page = audit_host + "http://192.168.50.60/openaudit/admin_nmap_input.php" nmap_ie_visible = "n" nmap_ie_auto_close = "y" nmap_ip_start = 1 nmap_ip_end = 254 nmap_syn_scan = "y" ' Tcp Syn scan
nmap_udp_scan = "y" ' UDP scan
nmap_srv_ver_scan = "y" ' Service version detection.
nmap_srv_ver_int = 9 ' Service version detection intensity level. Values 0-9, 0=fast
' Standard audit section
'
audit_location = "r"
verbose = "n"
audit_host="http://192.168.50.60"
online = "yesxml"
strComputer = ""
ie_visible = "n"
ie_auto_submit = "y"
ie_submit_verbose = "n"
ie_form_page = audit_host + "http://192.168.50.60/openaudit/admin_pc_add_1.php"
non_ie_page = audit_host + "http://192.168.50.60/openaudit/admin_pc_add_2.php"
input_file = "pc_list_file.txt"
'
' Email authentication
'
'
email_to = "paulo@paulojr.info"
email_from = "paulo@paulojr.info"
'email_sender = "Open-AudIT"
email_server = 192.168.50.60 ' IP address or FQDN
email_port = "25" ' The SMTP port
email_auth = "1" ' 0 = Anonymous, 1 = Clear-text Authentication, 2 = NTLM
email_user_id = "paulo@teste.com" ' A valid Email account in user@domain format
email_user_pwd = "12345" ' The SMTP email password
email_use_ssl = "false" ' True/False
email_timeout = "90" ' In seconds
audit_local_domain = "y"
'
' Set domain_type = 'nt' for NT4 or SAMBA otherwise leave blank or set to ldap
'domain_type = "nt"
local_domain = "LDAP://example.local"
'
' Example Set Domain name for NT ONLY for LDAP use the above format
' NOTE This is Case Sensetive. See the example below.
'
'local_domain = "WinNT://IEXPLORE"
'local_domain = "WinNT://"
'
hfnet = "n"
Count = 0
number_of_audits = 10
script_name = "audit.vbs"
monitor_detect = "y"
printer_detect = "y"
software_audit = "y"
uuid_type = "uuid"
'
' Nmap section
'
nmap_tmp_cleanup = true ' Set this false if you want to leave the tmp files for analysis in your tmp folder
nmap_subnet = "192.168.50." ' The subnet you wish to scan
nmap_subnet_formatted = "192.168.050." ' The subnet padded with 0's
nmap_ie_form_page = audit_host + "http://192.168.50.60/openaudit/admin_nmap_input.php" nmap_ie_visible = "n" nmap_ie_auto_close = "y" nmap_ip_start = 1 nmap_ip_end = 254 nmap_syn_scan = "y" ' Tcp Syn scan
nmap_udp_scan = "y" ' UDP scan
nmap_srv_ver_scan = "y" ' Service version detection.
nmap_srv_ver_int = 9 ' Service version detection intensity level. Values 0-9, 0=fast
Tudo foi instalado, e agora? Como vou alimentá-lo? Como vou auditar e criar o inventário dos computadores?
Auditar máquinas Windows
Em um computador com sistema operacional Windows, acesse pelo browser o endereço:http://ip_do_servidor/open-audit
Acesse o menu a sua esquerda e clique em ADMINISTRAÇÃO -> AUDITE ESTA MÁQUINA, conforme a imagem abaixo:
Execute este script e tenha paciência, pois em algumas máquinas pode demorar.
Quando o script acabar, acesse novamente o open-audit e verifique se a máquina já foi auditada, conforme a imagem abaixo:

Mas como auditar um Linux?
Bom, também existe esta opção, porém ela não é a das mais simples, pelo simples motivo que cada distribuição possui sua gama de pacotes, gerenciadores de pacotes e tudo mais.
Mas para auditar, faça o seguinte procedimento:
Edite o arquivo /var/www/openaudit/scripts/audit-linux.sh.
Altera a linha:
OA_SUBMIT_URL=http://salma/openaudit/admin_pc_add_2.php
para o endereço correto do servidor, como por exemplo:
OA_SUBMIT_URL=http://ip_do_servidor/openaudit/admin_pc_add_2.php
Salve o arquivo e dê permissão de execução através do comando:
# chmod a+x /var/www/openaudit/scripts/audit-linux.sh
Execute este script.
Podem retornar diversos erros e avisos, cada um deve ser analisado, pois no script testa se tal pacote é usado e tudo mais, vale a pena investigar cada aviso.
Dica de auditar automaticamente
Bom, existem diversas técnicas e maneiras de efetuar este procedimento de auditar ou inventariar automaticamente com este open-source, mas vou apresentar a que eu, Paulo Roberto Junior, uso.Primeiro, pegue aquele script .vbs que você usou para auditar aquela máquina com sistema operacional Windows e salve na rede do seu domínio com as devidas permissões. Pode salvar no SAMBA também, eu por exemplo o uso.
Nos scripts de logon dos usuários do Windows, edite a .bat que você usa ou a crie, caso não use, com o seguintes comandos:
@REM AUDITAR VIA OPENAUDIT
cscript \\192.168.80.2\cepem\suporte\auditar.vbs
cscript \\192.168.80.2\cepem\suporte\auditar.vbs
Reparem que alterei aquele nome gigante do script em .vbs para somente auditar.vbs, pois fica mais fácil administrar.
Quando o usuário se logar no domínio, ele vai executar o script e enviar para o servidor.
Atenção, o script devido a sua carga de requisições e dados a capturar pode demorar de acordo com a estação de trabalho e a rede local.
Fontes: Latinoware, Viva o Linux












{kind=link}